機械学習用語メモ
オークション・セール分析資料で出てくる用語を、実務判断で読みやすい粒度にまとめた補足ページです。
データ分割
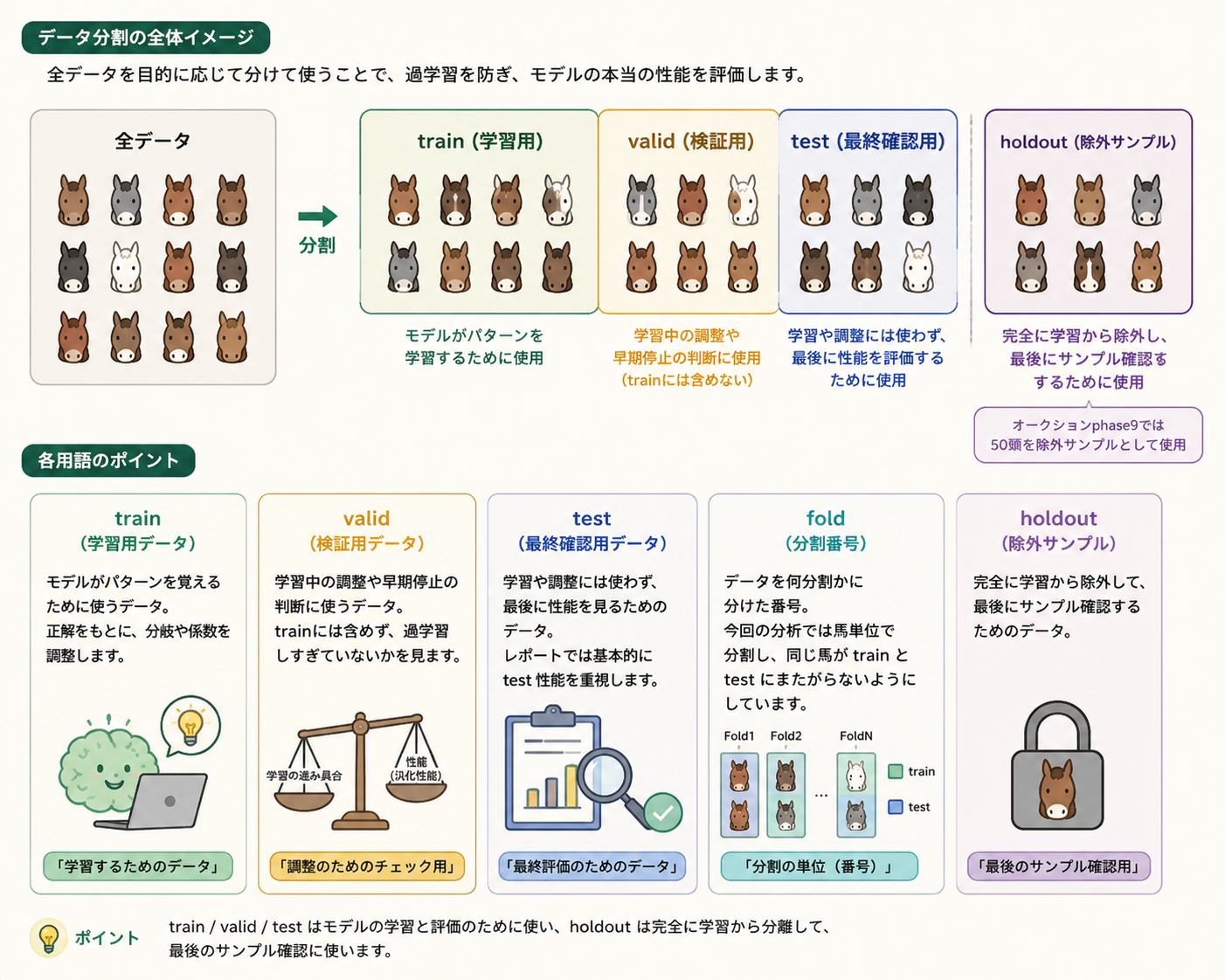
| train | 学習用データ。モデルがパターンを覚えるために使うデータです。ここで見た正解をもとに、分岐や係数を調整します。 |
|---|---|
| valid | 検証用データ。学習中の調整や早期停止の判断に使うデータです。trainには含めず、過学習しすぎていないかを見ます。 |
| test | 最終確認用データ。学習や調整には使わず、最後に性能を見るためのデータです。レポートでは基本的にtest性能を重視します。 |
| fold | データを何分割かに分けた番号です。今回の分析では馬単位で分割し、同じ馬がtrainとtestにまたがらないようにしています。 |
| holdout | 完全に学習から除外して、最後にサンプル確認するためのデータです。オークションphase9では50頭を除外サンプルとして使っています。 |
分類モデルの指標
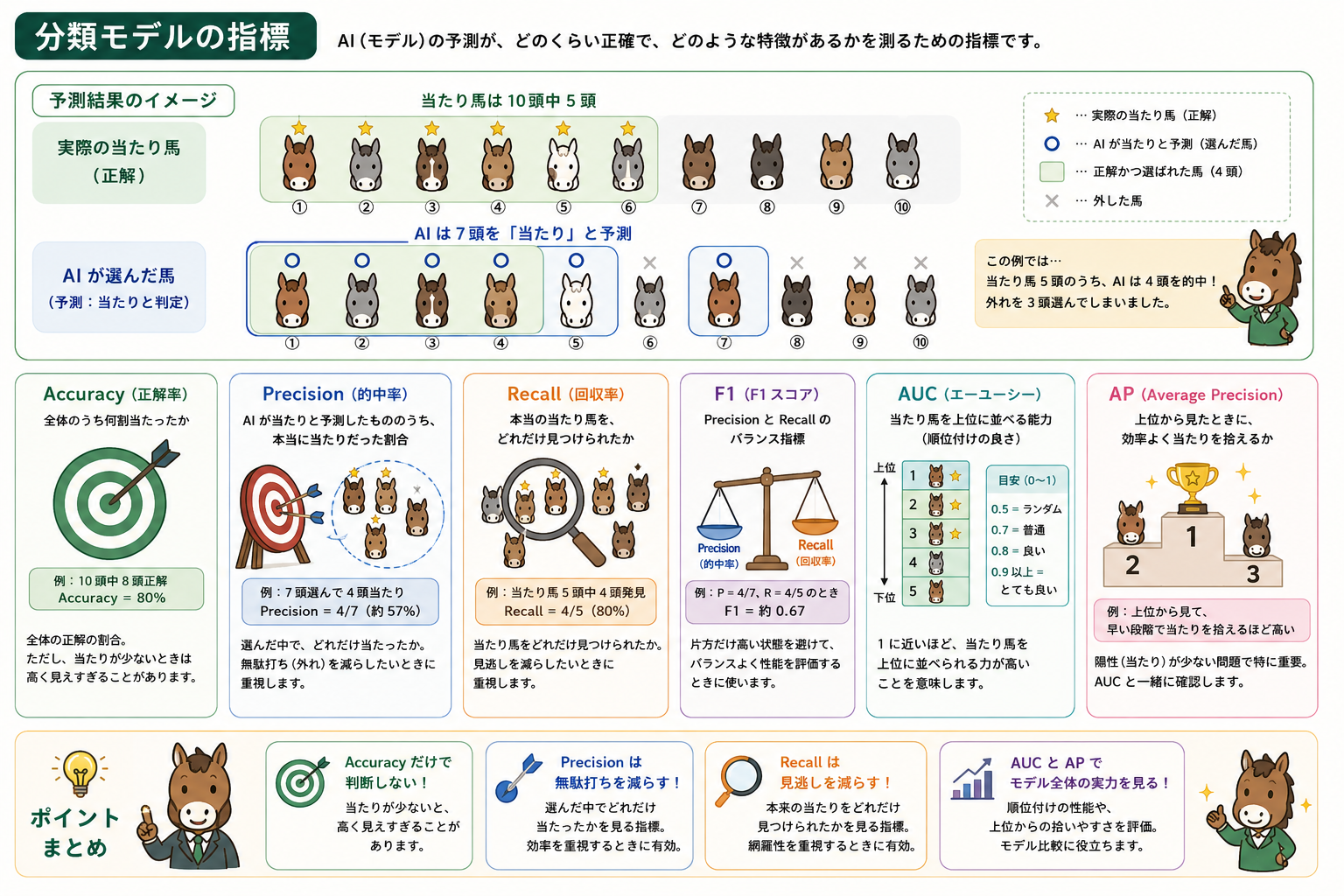
| AUC | 0〜1で表す分類性能です。ランダムに近いと0.5、良いほど1.0に近づきます。陽性を上位に並べる力を見る指標で、閾値を固定しない比較に向きます。 |
|---|---|
| AP | Average Precision。陽性候補を上位から見たとき、どれだけ効率よく当たりを拾えるかを見る指標です。陽性が少ない目的変数ではAUCと一緒に見ます。 |
| Accuracy | 正解率です。全体のうち何割が当たったかを表します。ただし陽性・陰性の偏りが大きい場合は高く見えすぎることがあります。 |
| Precision | 陽性と予測したもののうち、実際に陽性だった割合です。無駄打ちを減らしたいときに重視します。 |
| Recall | 実際の陽性のうち、どれだけ拾えたかです。見逃しを減らしたいときに重視します。 |
| F1 | PrecisionとRecallのバランス指標です。片方だけ高い状態を避けたいときに見ます。 |
| Brier | 予測確率のずれを測る指標です。小さいほど、確率の出し方が実態に近いと見ます。 |
| Logloss | 予測確率の外し方に厳しい指標です。自信満々に外すと悪化します。小さいほど良いです。 |
回帰モデルの指標

| R2 | 目的変数のばらつきをどれだけ説明できたかの指標です。1に近いほど良く、0付近は平均予測と同程度、マイナスは平均予測より悪い状態です。 |
|---|---|
| MAE | 平均絶対誤差です。予測値と実績値の差を絶対値で平均したものです。円やkgなど、元の単位で解釈できます。 |
| RMSE | 二乗平均平方根誤差です。大きな外れをMAEより強く罰します。外れ値に敏感です。 |
| Spearman | 順位相関です。実数を正確に当てるより、上位・下位の並び順が合っているかを見ます。落札価格など順位付けに使いたい場合に有用です。 |
目的変数の作り方
| 目的変数 | モデルに当てさせたい答えです。例: スピード指数75%点、休養120日以上、損益3分割、落札価格など。 |
|---|---|
| 特徴量 | 予測に使う入力情報です。例: 直近レース、募集コメント、馬体写真、血統、インブリードなど。 |
| 3分割の中抜き2分類 | 目的変数を下位・中位・上位の3つに分け、中位を学習から外して、下位と上位だけを分類する方法です。曖昧な中間層を外すため、差がはっきりした比較になります。 |
| 下位20%分類 | 目的変数の下位20%を1つのクラスとして扱う方法です。大外れ回避のように、悪い候補を見つけたいときに使います。 |
| 0/1分類 | 条件を満たすかどうかを0と1で表す分類です。例: 休養120日以上が1回以上あるか。 |
| 回帰 | 数値そのものを予測する方法です。例: 落札価格、馬体重平均、損益額など。 |
モデルと特徴量処理
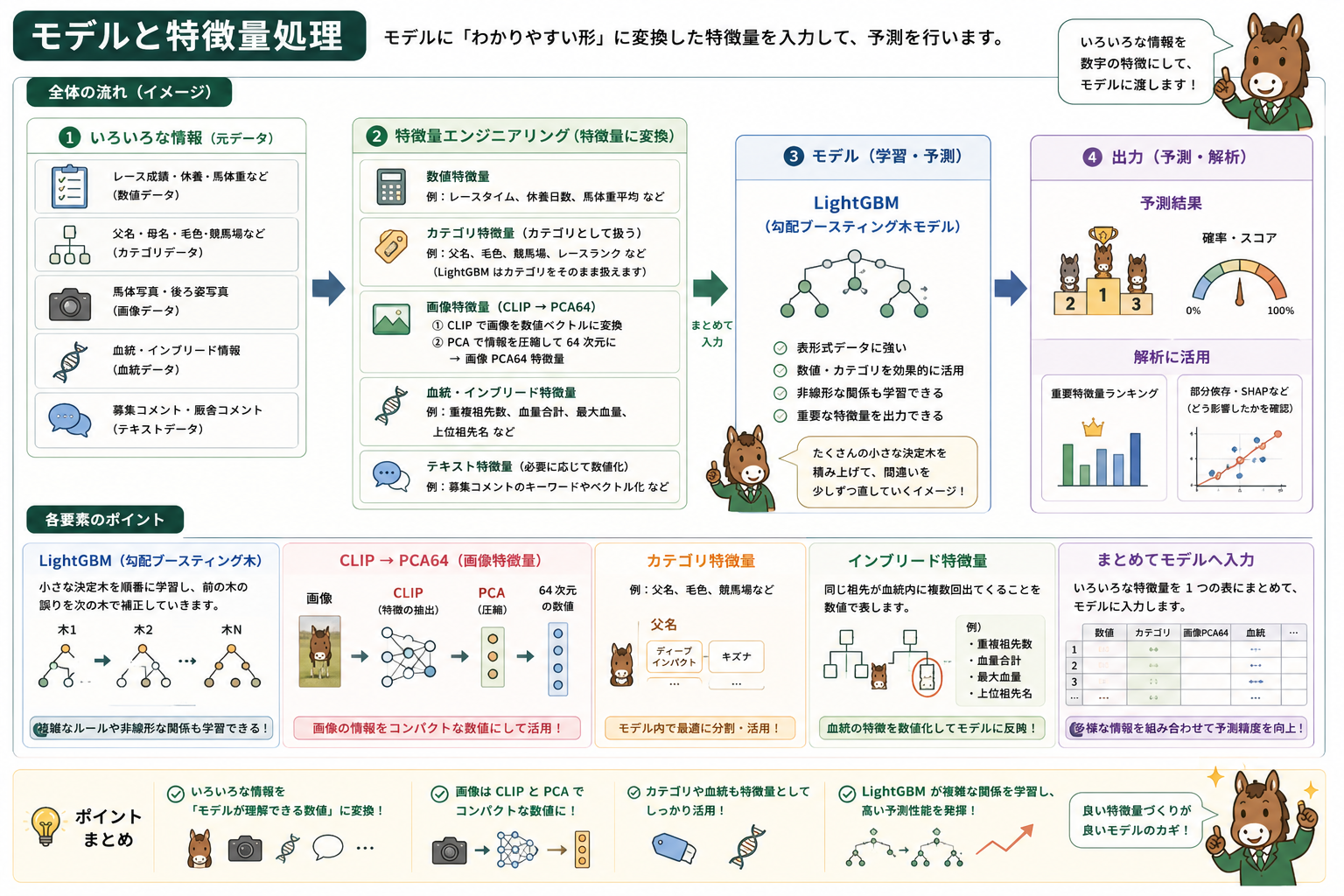
| LightGBM | 表形式データでよく使われる勾配ブースティング木モデルです。数値・カテゴリ特徴を扱いやすく、重要特徴量も出せます。初期検証や比較モデルとして使っています。 |
|---|---|
| CatBoost | カテゴリ特徴の扱いに強い勾配ブースティング木モデルです。父名・母名・毛色・レース条件・血統名のような文字列カテゴリを多く含むデータと相性がよく、最終版のオークション予測では主にCatBoostを使っています。 |
| 勾配ブースティング木 | 小さな決定木を何本も積み上げて、前の木の外れを次の木で補正していくモデルです。複雑な非線形関係を扱えます。 |
| CLIP | 画像を数値ベクトルに変換する画像モデルです。馬体写真や後ろ姿写真を、機械学習で扱える特徴量にするために使っています。 |
| PCA | 主成分分析。多次元の特徴量を、情報をなるべく残しながら少ない次元に圧縮する方法です。画像CLIP特徴を64次元に圧縮する用途で使っています。 |
| 画像PCA64 | 画像特徴を64個の数値に圧縮したものです。各成分は単純に「脚」「首」などとは直訳できず、画像全体の差を表す合成特徴として見ます。 |
| カテゴリ特徴 | 文字列や分類値の特徴量です。例: 父名、母名、毛色、競馬場、レースランクなど。LightGBMやCatBoostではカテゴリとして扱えます。 |
| インブリード | 同じ祖先が血統内に複数回現れることです。今回は重複祖先数、血量合計、最大血量、上位祖先名などを特徴量化しています。 |
重要特徴量
| gain | その特徴量を使った分岐によって、モデルの損失がどれだけ改善したかの合計です。大きいほど予測性能への貢献が大きいと見ます。 |
|---|---|
| split | その特徴量が木の分岐に使われた回数です。よく使われた特徴量ですが、何度も小さく効いただけでも大きくなるため、gainの補助として見ます。 |
| 重要特徴量TOP | LightGBMやCatBoostが予測時に効いたと判断した特徴量の上位です。因果関係を証明するものではなく、モデル内での利用度・貢献度です。 |
注意点
| リーク | 予測時点では本来使えない未来情報が特徴量に混ざることです。リークがあると精度が不自然に高くなります。今回の分析では目的変数側は未来を含み、特徴量側は予測時点で使える情報に寄せています。 |
|---|---|
| 過学習 | 学習データに合わせすぎて、未知データで性能が落ちる状態です。trainだけ良く、valid/testで悪い場合に疑います。 |
| 相関と因果 | 重要特徴量や相関が高いことは、必ずしも原因であることを意味しません。判断材料の候補として扱います。 |
| サンプル数 | 件数が少ない目的変数や偏りが強い目的変数は、指標がぶれやすくなります。特にセール側は情報量とサンプル構成に注意が必要です。 |
このページは指標の読み方を揃えるための補足です。実際の採否判断では、目的変数の性質、サンプル数、入力情報の時点、重要特徴量の中身を合わせて確認します。